RAG Troubleshooting GPT Assistant AI
A self-built AI assistant that indexes my technical docs/runbooks/logs for semantic troubleshooting and faster incident resolution.
Last updated: Feb 27, 2026
Tech
PythonFastAPIOpenAI APIVector DB (Pinecone)AWS Lambda (ingestion / embedding jobs)Document pipelines
Highlights
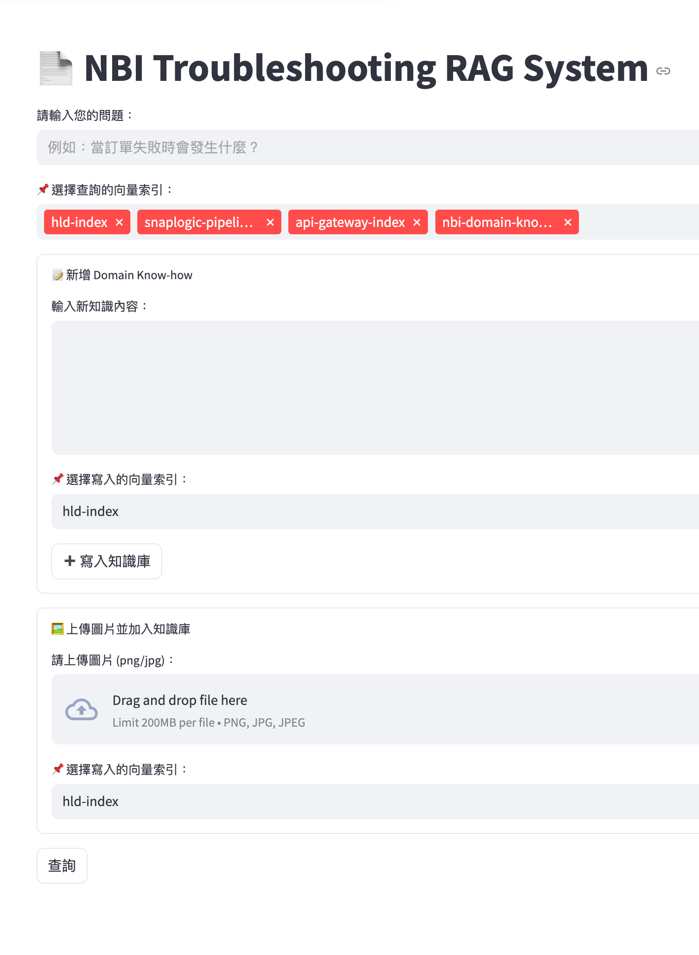
- RAG over personal/internal knowledge: ingest docs → chunk → embed → retrieve → answer with citations/context.
- Designed a memory loop to continuously improve answers from feedback and new documents.
- Built as a practical troubleshooting copilot for real production workflows (cloud + DevOps).
Metrics / Notes
- Reduced time-to-context-switch during investigations by making domain knowledge searchable and explainable.
- Reusable architecture for other domains (e.g., video transcription, argument analysis).
Tags
RAGLLMDevOps
Why I built it
In cloud support and DevOps work, the hardest part is rarely the command you run—it’s finding the right context: runbooks, postmortems, internal docs, logs, diagrams, and past cases.
This project turns that scattered knowledge into a searchable, conversational assistant.
How it works (simplified)
- Ingestion: documents/logs/design specs are collected and normalized
- Chunking + Embeddings: text is split and embedded into a vector database
- Retrieval: relevant chunks are retrieved based on semantic similarity
- Answering (RAG): LLM generates an answer grounded in retrieved context
- Memory loop: feedback and new knowledge improve future responses
Demo
- External demo: the hosted app (link above)
- Portfolio demo: a lightweight “prototype UI” in the Lab page
Related writing
I documented the motivation and design decisions in my blog posts on this site.